これまでマーケットプレイス (サポートサイト) に掲載されていたPFAモデル予測のプラグインは、今後サポートされません (2023年11月1日をもって終了)。詳細はこちらの記事をご確認ください。これらのコードのレガシーバージョンへのアクセスをご希望の場合は、Yellowfin サポートチームまでお問い合わせください。
PFAトランスフォーメーションステップは、PFAファイルに保存された高度なデータサイエンスモデルをYellowfinにインポートし、データトランスフォーメーションモジュールから、データへ適用することができます。
こちらの項目を確認する前に、データトランスフォーメーションモジュールについて事前に理解をしておくのが理想的です。
前提条件
このステップの使用において、事前にセットアップしなくてはいけないシステムはありませんが、主要な要件は以下の通りです。
- PFA形式で保存されたデータサイエンスモデル。このファイルをサポートしているファイル拡張子は、JSON 、またはYAMLです。
- PFAのプラグイン。
- モデル上で実行するデータ。これは、インプットステップからインポートされます。
一般的なワークフロー
こちらがプロセスの簡単な概要です。こちらの項目では、これらのステップの大部分について、詳細に説明します。
- YellowfinインスタンスへPFAのプラグインをインストールします。プラグインのインストール方法は、こちらを参照してください。
- Yellowfinのデータトランスフォーメーションモジュールを使用して、トランスフォーメーションフローを作成します。これには、モジュールへのデータインポートと、必要に応じて、その他トランスフォーメーションの適用が必要です。
- フローにPFAトランスフォーメーションステップを使用し、これを設定します。(ステップの設定方法は、以下の情報を参照してください。)
- ステップを実行し、モデルがデータを使用して生成する出力を確認します。
トランスフォーメーションフローでのPFAモデルの使用
PFAモデル予測ステップを使用して、Yellowfinへデータサイエンスモデルを統合する方法について説明します。- 高度な分析モデルを構築し、PFA形式でこれを保存します。ファイルタイプはJSON、もしくはYAMLです(説明の中ではこのファイルを、PFAファイルと言います)。
- Yellowfinのデータトランスフォーメーションモジュールへ移動します。(「作成」ボタン>「トランスフォーメーションフロー」)
- データを取得するインプットステップ)から、トランスフォーメーションフローの作成を始めます。(基礎的なフローの作成方法は、こちらを参照してください。また、他のデータの取得方法については、こちらを参照してください)
- 取得されたデータが、データプレビューパネルに表示されます。さらにデータをトランスフォーメーションするために、ステップを追加することもできます。
- PAFステップを使用してデータサイエンスモデルをインポートする準備が整ったら、以下の手順に従います。
トランスフォーメーションステップ一覧から、PFAステップをキャンバスへドラッグします。(PFAステップアイコンは、初めてドラッグされた際に、デフォルトで赤く表示されるようになっています。これは、ステップが設定されていないことを示すためです)
こちらのステップが表示されない場合は、PFAのプラグインがインストールされているかを確認してください)
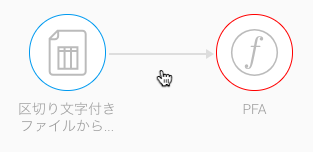
- 接続ポイントを使用して、最後のステップをPFAステップへ接続します。
- PFAステップをクリックすると、トランスフォーメーションフローパネルに設定が表示されます。
- YAML、またはJSONオプションを選択して、ファイルの拡張子を指定します。
- モデルを含むPFAファイルをアップロードします。ファイルはドラッグ&ドロップ、またはファイルパスの指定によりアップロードすることができます。
- デフォルトのドラッグ&ドロップオプションを使用している場合は、指定されたエリアへ対象のファイルをドラッグします(または、エリアをクリックして、対象のファイルを選択します)
注意:不適切なファイルタイプがドラッグされた場合、以下のようなエラーメッセージが表示されます。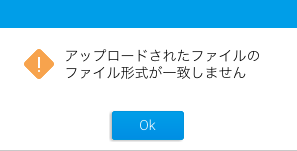
パスからPFAファイルを読み込む場合は、「Load from Path(パスからの読み込み)」トグルを有効にし、ファイルパス、またはURLを入力します。
サーバファイル、またはウェブサイトのURLの完全パスを入力します。URLの場合は、「http:」、または「https:」で始まることを確認してください。
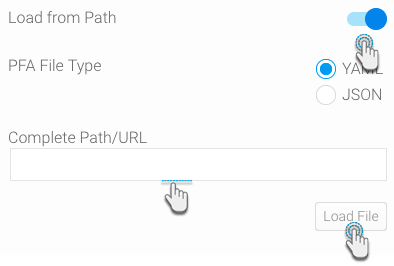
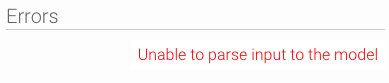
- 次に、「Load File(ファイルの読み込み)」ボタンをクリックします。ステップは、ファイルの解析を開始しますが、ファイルパスが不正確な場合は、以下のエラーメッセージが表示されます。
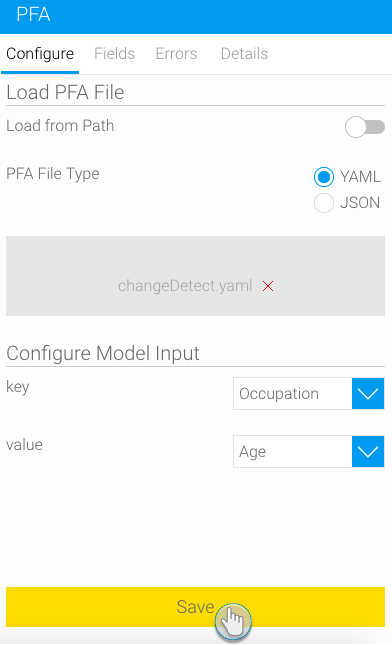
ファイルのアップロードが完了したら、モデルの入力を設定するさらなるフィールドが表示されます。(注意:これらのフィールドの表示には時間を要する場合があります)

- 注意:これらのフィールドは、変数の名前でラベルされている場合がありますが、PFAファイル内で名前が指定されていない場合は、変数のタイプが表示されます。例:

- モデルのデータを、以前のステップから取得されるデータとマッピングします。データ型が一致することを確認してください。(ユーザーはPFAファイル内のモデルを熟知しているため、正確なマッピングができると見なされます)
- 「Save(保存)」ボタンをクリックします。
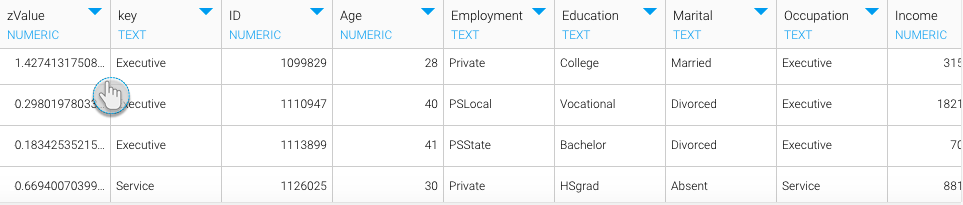
- データプレビューパネルのカラム(列)に、データサイエンスモデルにより生成された結果が表示されます。注意:この出力カラム(列)に表示される名前は、PFAファイル内で指定されたものに準じます。出力の名前が指定されていない場合、カラム(列)はデフォルトで「PFA Output(出力)」とラベルされます。