概要
高度な関数は、最初のクエリ―結果に対して後処理の計算を適用することで、結果を変換するために使用します。これらの関数は、SQLクエリ―の一部ではなく、Javaコードにより実行されるため、データベースには依存しません。利用可能な関数
Yellowfinは、定義済みの関数を用意していますが、管理者によって、組織やレポート要求に特化した関数が追加されることもあります。利用可能な関数は、以下の一覧を展開して確認をしてください。
高度な関数のカスタマイズの例 – Rの統合
高度な関数のカスタマイズの例として、レポートでRを使用する方法を示します。
Rスクリプトを記述する
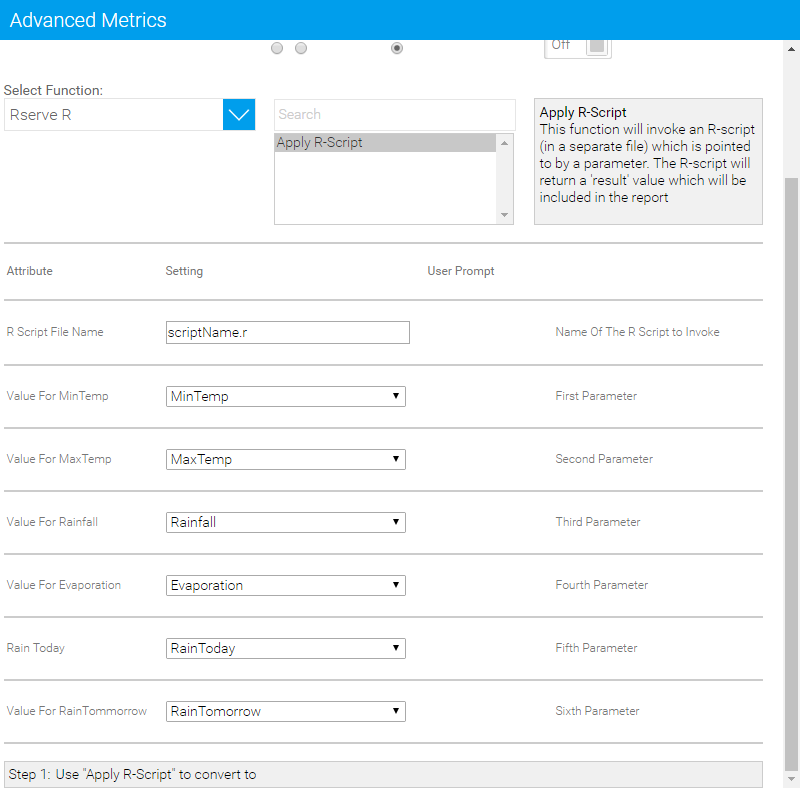
Rスクリプトの呼び出し
一度インストールをすれば、高度な関数メニューから、こちらの機能を使用することができます。
関数の適用
レポートビルダー - データステップ
高度な関数を適用する場合、まず始めに、関数を適用するフィールドを表に追加しなくてはいけません。関数を適用する場合、表内にフィールドのコピーが2つ必要になることがあります。ひとつは元の値(売上額、など)を表示するため、もうひとつは関数(例えば、売上額の最上位から10位を表示、など)を適用するために必要です。
レポートビルダーのデータステップで、表内のフィールドに関数を適用するためには、以下の手順を実行します。
以下のいずれかの方法で、フィールドのドロップダウンメニューを開きます。
- カラム(列)/ ロウ(行)一覧から

- 表のプレビューから
- カラム(列)/ ロウ(行)一覧から
- 一覧から「高度な関数」オプションを選択し、高度な関数設定画面を開きます。
- 以下の関数オプションを入力します。
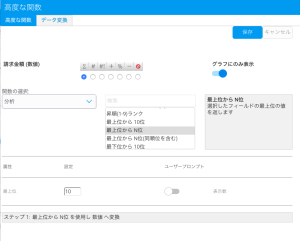
- フィールドに適切な集約を適用します。これにより、必要なすべての集約の最上位に、この関数が適用されます。
- 「分析」、「統計」、「テキスト」から、適用したい関数タイプを選択します。
- 一覧から使用したい関数名を選択します。関数名を選択すると、その関数の説明が横のボックスに表示されます。いくつかの関数は、関数を選択してから、パラメーターの定義を要求されます。
- 関数を「グラフ」ページのみに表示するように設定することもできます。これはレポートの表から対象のフィールドを非表示にしますが、カラム(列)/ ロウ(行)一覧から、これを閲覧、編集することが可能です。これにより、表示目的で関数を適用するフィールドのコピーを追加する場合に、追加されたフィールドで表を煩雑にすることがありません。

- 関数の定義が完了したら、「保存」ボタンをクリックして、適用します。
レポートビルダー - グラフステップ
レポートビルダーのグラフステップから、表内のフィールドに関数を適用する場合は、以下の手順を実行します。
- 画面の左下部にある「+」ボタンをクリックします。
- 「高度な関数」を選択して、使用するフィールドを一覧から選択し、高度な関数設定画面を開きます。
- 関数オプションを入力します。
- フィールドに適切な集約を適用します。これにより、必要なすべての集約の最上位に、この関数が適用されます。
- 「分析」、「統計」、「テキスト」から、適用したい関数タイプを選択します。
- 一覧から使用したい関数名を選択します。関数名を選択すると、その関数の説明が横のボックスに表示されます。いくつかの関数は、関数を選択してから、パラメーターの定義を要求されます。
- 関数を「グラフ」ページのみに表示するように設定することもできます。これはレポートの表から対象のフィールドを非表示にしますが、データステップのカラム(列)/ ロウ(行)一覧から、これを閲覧、編集することが可能です。これにより、表示目的で関数を適用するフィールドのコピーを追加する場合に、追加されたフィールドで表を煩雑にすることがありません。
- .関数の定義が完了したら、「保存」ボタンをクリックして、適用します。
レポートビルダー – デザインステップ
レポートビルダーのデザインステップで、表内のフィールドに関数を適用するには、以下の手順を実行します。
- フィールドのドロップダウンメニューを開きます。
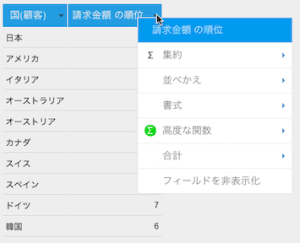
- 一覧から「高度な関数」オプションを選択して、高度な関数設定画面を開きます。
- 関数オプションを入力します。
- フィールドに適切な集約を適用します。これにより、必要なすべての集約の最上位に、この関数が適用されます。
- 「分析」、「統計」、「テキスト」から、適用したい関数タイプを選択します。
- 一覧から使用したい関数名を選択します。関数名を選択すると、その関数の説明が横のボックスに表示されます。いくつかの関数は、関数を選択してから、パラメーターの定義を要求されます。
- 関数を「グラフ」ページのみに表示するように設定することもできます。これはレポートの表から対象のフィールドを非表示にしますが、データステップのカラム(列)/ ロウ(行)一覧から、これを閲覧、編集することが可能です。これにより、表示目的で関数を適用するフィールドのコピーを追加する場合に、追加されたフィールドで表を煩雑にすることがありません。
- 関数の定義が完了したら、「保存」ボタンをクリックして、適用します。
データ変換の適用
以下の手順を実行することで、フィールドのデータを変換することができます。上記で説明されているように、「高度な関数」表示を開きます。
「データ変換」タブを選択します。 こちらの画面から、変換したいデータを選択します。
変換に適切な集約を選択します。
選択した変換を適用するために、「追加」ボタンをクリックします。選択したデータタイプで使用可能な変換の一覧が表示されます。デフォルト設定では、「Javaデータコンバーター」と「数値除算コンバーター(値を1,000で除算します)」表示されます。
画面の指示に従って操作し、「保存」ボタンをクリックします。
必要に応じて、「追加」ボタンをクリックして新しいタイプを作成することで、複数のコンバーターをデータに追加することができます。