概要
Yellowfinでは、SQLデータベースにアウトプットすることで、トランスフォーメーションしたデータをデータベーステーブルへ保存することができます。こちらのステップの設定をするためには、対象のデータベースやテーブル、必要な更新のタイプ、マッピングするフィールドなど、関連する様々な設定を定義しなくてはいけません。こちらの項目では、それぞれの詳細について紹介します。
警告
既存のソースデータを上書きしないために、アウトプットステップの設定時には、細心の注意が必要です。データベースへのアウトプットステップには様々なオプションがあり、テーブルの削除、データの削除、新規ロウ(行)の追加、既存データの更新などを行うことができます。トランスフォーメーションフローの構築には、テスト環境の使用をお勧めします。また、編集モードの場合、デフォルトでアウトプットステップは無効に設定されています(デザインモードオプションでの実行を参照してください)
オプションの理解
テーブル作成オプション
| テーブル作成タイプ | 説明 |
| 既存を使用 | 選択した既存のテーブルへデータを保存します。 |
| 存在しない場合に作成する | 指定したテーブルが存在しない場合は、新規作成をし(または、作成された後に)、データを保存します。 |
| 既存をドロップ | 既存のテーブルを削除し、常に新規作成をします。このオプションは、既存のデータを保持する必要が無い場合にのみ使用してください。 |
| メタデータに矛盾がある場合にドロップ | トランスフォーメーションフローとテーブルのデータ間のメタデータに矛盾がある場合(矛盾とは、フローファイル内のフィールド/カラム(列)数が、テーブル内と異なる場合や、データ型が異なる場合などを指します)、テーブルを削除し、新規作成をすることでデータを保存します。矛盾が無い場合は、既存のテーブルを使用します。このオプションは、既存のデータを保持する必要が無い場合にのみ使用してください。 |
多くの場合は、「既存を使用」をオプションを使用します。データベース管理者は、データトランスフォーメーションの対象になるテーブルを作成し、関連するセキュリティアクセスを割り当てます。
稀に、対象のテーブルが存在しない場合があります。この時適切なセキュリティアクセス権が付与されていれば、Yellowfinがテーブルを作成します。存在しない場合に作成するオプションは、指定したテーブルが存在しない場合にテーブルを作成します。これは通常、トランスフォーメーションフローを初めて実行する場合に発生し、その後は既存のテーブルが使用されることになります。既存をドロップは、常にテーブルを削除し、新しく作成します。テーブルに保存されている可能性のあるデータをすべて削除するので、使用には細心の注意が必要です。メタデータに矛盾がある場合にドロップも同様に、テーブル構造とフロー内に含まれるデータに相違がある場合は、テーブルを削除し、新しく作成します。このオプションもデータを削除するため、使用には細心の注意が必要です。
更新タイプ
| 更新タイプ | 説明 |
| 挿入 | 既存のデータの最後にデータを追加をします。 |
| 切り捨て | 既存のすべてのデータを新しい値に置き換えます。これは既存のデータを削除するので、使用には細心の注意が必要です。 |
| 更新 | トランスフォーメーションフローに存在するロウ(行)と一致するデータベース内のフィールドの値を更新します。このオプションは既存のデータを上書きするため、使用には細心の注意が必要です。 |
| 更新して挿入 | トランスフォーメーションフローに存在するロウ(行)が一致するデータベース内のフィールドの値を更新します。このオプションは既存のデータを上書きするため、使用には細心の注意が必要です。一致するロウ(行)が存在しない場合は、新規ロウ(行)を挿入します。 |
ステップの設定
- トランスフォーメーションフロービルダーの画面左側からアウトプットステップボタンをクリックして、すべてのステップを表示します。
- 一覧から「SQLデータベースにアウトプット」ステップをキャンバスへドラッグします。
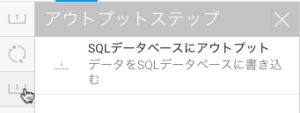
- ステップをクリックして、トランスフォーメーションフローパネルに設定詳細を表示します。
- 一覧からデータベースを選択します。書き込み可能なデータソースのみが表示されます。
- テーブル作成オプションを選択します。テーブル作成オプションの詳細は、こちらを参照してください。
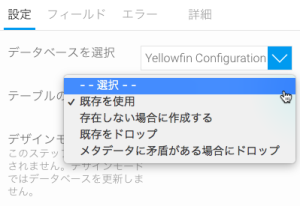
- 選択したプロセスを継続します。
- 「既存を使用」を選択した場合、データを保存する既存のテーブルを選択します。

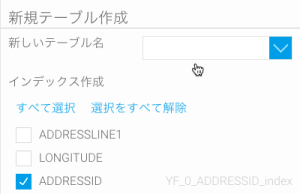
- 「存在しない場合に作成する」を選択した場合、新しいテーブル名を入力します。オプション設定として、インデックスを作成するテーブルフィールドを選択することができます(注意:インデックスは、クエリーパフォーマンスを改善するために使用します。こちらのオプションを使用すべきか不明な場合は、システム管理者に問い合わせをしてください)。
- 「既存をドロップ」を選択した場合、新しいテーブル名を入力します。必要に応じて、インデックスを作成する任意のフィールドを選択します。(そして、次の2つの手順をスキップします)
- 「メタデータに矛盾がある場合にドロップ」を選択した場合、新しいテーブル名を入力し、トランスフォーメーションフローに存在するフィールドが、テーブル内よりも多い場合に、既存のテーブルをドロップするかどうかを指定します。

- 「既存を使用」を選択した場合、データを保存する既存のテーブルを選択します。
更新タイプから、既存テーブルの更新方法を選択します。すべてのオプションの詳細は、こちらを参照してください。
「更新」、または「更新して挿入」オプションを選択した場合、さらなるロウ(行)の一致が要求されます。これは、更新するフィールドを指定するために、WHERE節を設定することで実行されます。
アウトプットデータベース内の既存のレコードを更新する場合、次の2つのタイプのカラム(列)/フィールドを指定しなくてはいけません。
参加フィールド:フローテーブルがデータベーステーブルに参加するためのフィールドです。このフィールドは、両方のテーブルに一致する値を含む必要があります。このフィールドには「参加」オプションが使用されます。
設定フィールド:データベースを更新するためにその値を使用するフィールドです。このフィールドには「設定」オプションが使用されます。
何も選択されていない場合は、フィールドはフローの一部として参加、または更新に使用されることはありません。

- こちらのカラム(列)で「参加」オプションを選択します。

- 次に、アウトプットデータベースの更新に使用するフィールドを選択し、「設定」オプションを選択します(これにより、データベースカラム(列)は、このフィールドの値に置き換えられます。)

- こちらのカラム(列)で「参加」オプションを選択します。
- このアウトプットステップをデザインモードで実行するには、「デザインモードで実行」トグルを有効にします。警告を参照してください。

- 設定が完了したら、「適用」ボタンをクリックして、設定内容を保存します。