これまでマーケットプレイス (サポートサイト) に掲載されていたPFAモデル予測のプラグインは、今後サポートされません (2023年11月1日をもって終了)。詳細はこちらの記事をご確認ください。これらのコードのレガシーバージョンへのアクセスをご希望の場合は、Yellowfin サポートチームまでお問い合わせください。
こちらの項目は、レポートビルダーの高度な関数を設定することで、PFAファイルに保存されたデータサイエンスモデルを、Yellowfin内で使用する方法について紹介します。
前提条件
PFAのために設定が必要なシステムはありません。主要な要件は以下の通りです。
- PFA形式で保存されたデータサイエンスモデル。ファイルの拡張子はJSON、またはYAMLです。
- PFAのプラグインのインストール。より詳細な情報は、Yellowfin サポートチームにお問い合わせください。
手順
高度な関数を使用し、PFAファイルを通して、プラットフォームへデータサイエンスモデルを統合するには、以下の手順に従います。
- PFA形式(.json/.yaml)でモデルを保存します。
- 予測を生成するデータを使用して、レポートを作成します。
- 予測が生成されるデータと同様のデータ型を持つカラム(列)をドラッグします。例えば、モデルが性別などのカテゴリー予測を返す場合は、テキスト型のカラム(列)をドラッグします。
- カラム(列)の書式設定ドロップダウンから、「高度な関数」をクリックします。
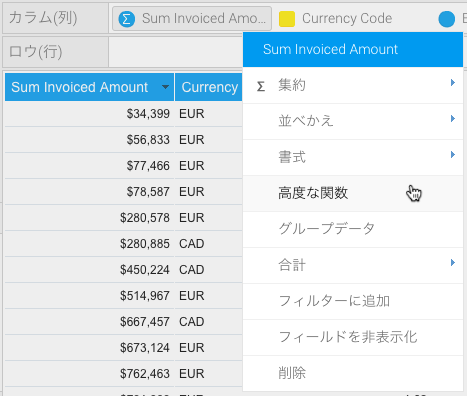
- ドロップダウンから「Statistical(統計)」オプションをクリックし、「PFA」オプションを選択します。詳細な設定オプションが表示されます。
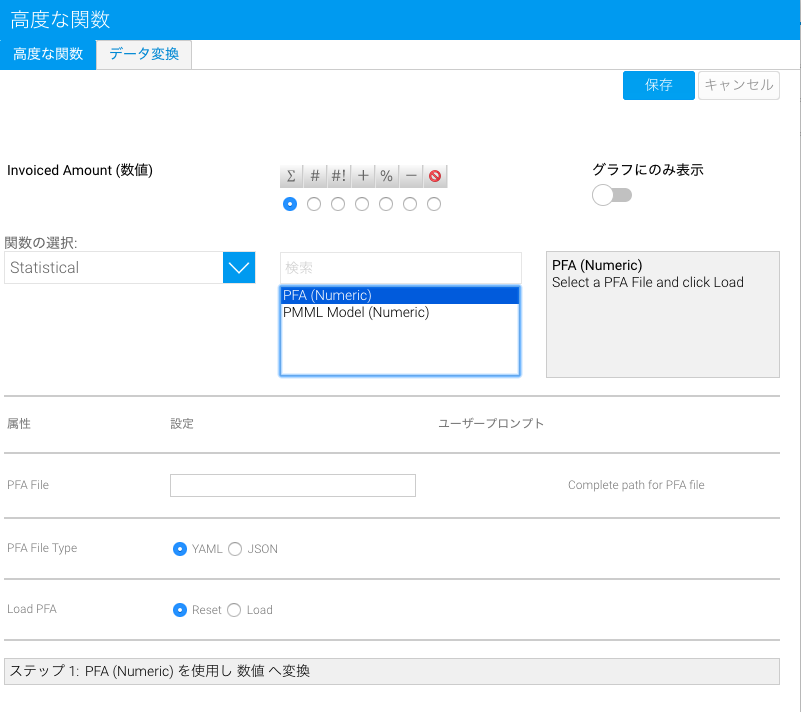
- PFAファイルへの完全ファイルパス、またはURLを入力します。
- 「YAML」、または「JSON」オプションを選択することで、アップロードするPFAファイルの拡張子を指定します。

- 「Load(読み込み)」オプションを選択します。Yellowfinが指定されたファイルを読み込むことができた場合は、詳細な設定オプションが表示されます。
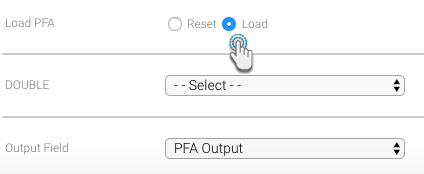
- モデルに必要な入力カラム(列)をマッピングします。これらのフィールドは、変数名でラベルされますが、PFAファイル内で名前が指定されていない場合は、以下のように変数のデータ型が表示されます。

- 出力フィールドを選択します。

- 高度な関数画面の上右隅にある「保存」ボタンをクリックします。

- 注意:ファイルの読み込みに問題が発生した場合は、モデルに必要なデータ型と同様の、有効なカラム(列)を提供しているか、またはYellowfin.logに出力されるエラーを確認しましょう。